UK 2015 Election
I like to check out new and enhanced R packages, particularly those relating to socio-economic issues and sports
A recent new entry is hansard, which pulls data from the UK Parliament API
Other required packages, which I will make extensive use of in future code extracts, are tidyverse, for data preparation and processing, and plotly, for a wide set of interactive graphics
The election_results() function retrieves all the results. It takes about 10 seconds to process so I have saved it in a csv file for retrieval in any future manipulation
library(hansard)
library(plotly)
library(tidyverse)
# This function retrieves all the election results and takes a few seconds and has been saved previously
#election_results <- election_results()
#write_csv(election_results,"data/election_results.csv")
#read the saved file
results <- read_csv("data/election_results.csv")
# view data.frame
results
## # A tibble: 1,327 x 9
## `_about` electorate majority
## <chr> <int> <int>
## 1 http://data.parliament.uk/resources/382387 64808 8361
## 2 http://data.parliament.uk/resources/382389 64031 3506
## 3 http://data.parliament.uk/resources/382391 62364 12408
## 4 http://data.parliament.uk/resources/382393 62860 3282
## 5 http://data.parliament.uk/resources/382395 67165 3431
## 6 http://data.parliament.uk/resources/382397 73320 9911
## 7 http://data.parliament.uk/resources/382399 64300 4027
## 8 http://data.parliament.uk/resources/382401 73826 5675
## 9 http://data.parliament.uk/resources/382403 47263 4826
## 10 http://data.parliament.uk/resources/382405 68352 12007
## # ... with 1,317 more rows, and 6 more variables: resultOfElection <chr>,
## # turnout <int>, constituency._about <chr>,
## # constituency.label._value <chr>, election._about <chr>,
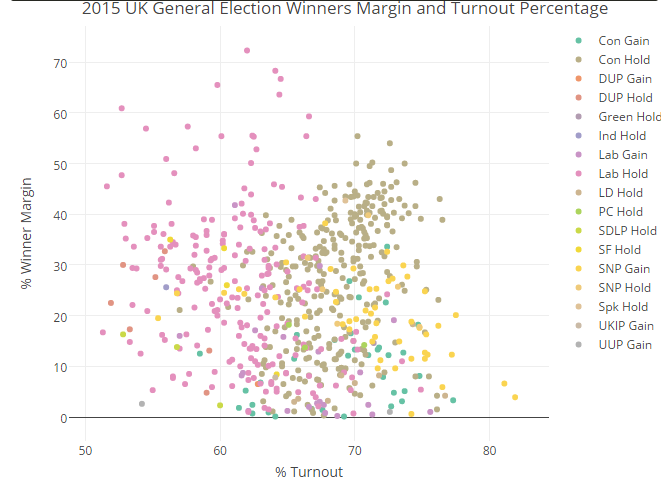
## # election.label._value <chr>Let’s say we were interested in how the size of majority is associated with the level of turnout. It might be hypothesised that those constituencies where a tight race was anticipated would have the highest turn-outs - where every vote might count
# filter out unwanted rows and calculate a couple of percentages
df <- results %>%
filter(election.label._value == "2015 General Election") %>% #650
mutate(
to_pc = round(100 * turnout / electorate, 1),
margin_pc = round(100 * majority / turnout, 1)
)
# plot the data, adding a custom info-action
df %>%
plot_ly(
x = ~ to_pc,
y = ~ margin_pc,
color = ~ resultOfElection,
hoverinfo = "text",
text = ~ paste0(
constituency.label._value,
"<br>",
resultOfElection,
"<br>Turnout:",
to_pc,
"%<br>Margin:",
margin_pc,
"%"
)
) %>%
layout(
title = "2015 UK General Election Winners Margin and Turnout Percentage",
xaxis = list(title = "% Turnout"),
yaxis = list(title = "% Winner Margin")
) %>%
config(displayModeBar = F, showLink = F)Well maybe.. but for those of you wanting to model it feel free. What is highlighted is the ‘wasted’ votes in Labour strongholds.
Hover over any point, if desired after selecting and zooming, for more details
There are plenty more functions within the package and the creator, Evan Odell is actively developing it