Analyzing some Premier League data
I recently had some fan-mail! The author suggested I write a book on the “practical considerations when building shiny”. That’s not going to happen, but I thought I would go into an example (warts and all) of how I proceed from an idea to an output which might end up as a tweet, flexdashboard, blog post or just plain binned (and not in the histogram sense)
There are plenty of great tutorials out there but most just provide the finished article with code. My efforts are much messier but with some practice and the wonderful tools available in R, even a hobbyist can reasonably come up with something unique - albeit usually pretty meaningless.
I have been collecting English Premier League soccer/football data since 1991 - that is before the league even existed - so I have a pretty good vault of data to provide at least trivia, preferably that which users can interact with.
Often a commentator’s phrase will spark something off in my head and this happened when in the Hull v Everton game (I know, I know but it was the only one played last Friday night) the home team scored an early goal and it was mentioned that this was the first time Hull had scored in the first 25 minutes of a game this season. Even as a relegation-threatened team, this did seem somewhat surprising so I thought I would check it out.
I have two relevant data frames: goals (which provides the scorer and time of goal) and playerGame (which links the scorer to the date of game and team played for). Along with many others these are updated following every round of PL matches
Along with the data, I will need to include the usual libraries, plotly (for interactive plotting), DT for tabular output and tidyverse(which covers pretty much everything else)
#knitr::opts_chunk$set(collapse = TRUE)
library(plotly)
library(DT)
library(tidyverse)
playerGame <- readRDS("data/playerGame.rds")
goals <- readRDS("data/goals.rds")
standings <- readRDS("data/standings.rds")OK, this is where it gets ugly and may (just may) get me to be more consistent with variable/column naming
# lets see what variables are available in each dataframe
sort(names(playerGame))## [1] "age" "Assists" "born"
## [4] "CARD" "city" "COUNTRY"
## [7] "day" "FEE" "gameDate"
## [10] "Gls" "joined" "LASTNAME"
## [13] "left" "MATCHID" "mins"
## [16] "MissedPenalty" "name" "OFF"
## [19] "offA" "on" "Opponents"
## [22] "OwnGoal" "PENS" "PERMANENT"
## [25] "PLAYER_MATCH" "PLAYER_TEAM" "PLAYERID"
## [28] "plGameOrder" "plGameOrderApp" "plTmGameOrder"
## [31] "plTmGameOrderApp" "plYrGameOrder" "plYrGameOrderApp"
## [34] "plYrTmGameOrder" "plYrTmGameOrderApp" "POSITION"
## [37] "season" "st" "START"
## [40] "subOn" "TEAMMATCHID" "TEAMNAME"
## [43] "venue"sort(names(goals))## [1] "GOALS" "METHOD" "PLACE"
## [4] "PLAY" "PLAYER_MATCH" "PLAYER_MATCH_GOAL"
## [7] "TEAMMATCHID" "TIME"#There are common fields(PLAYER_MATCH and TEAMMATCHID) for joining, the season and TEAMNAME in 'playerGame' and TIME in 'goals'
# join data
df <- goals %>%
left_join(playerGame) %>%
# restrict to current season and games prior to the current date
filter(season=="2016/17" &gameDate<"2016-12-30") %>%
# just provide columns of interest
select(TEAMNAME,TIME)
glimpse(df)## Observations: 508
## Variables: 2
## $ TEAMNAME <chr> "Swansea", "West Brom", "Tottenham H", "Everton", "Hu...
## $ TIME <int> 82, 74, 59, 5, 57, 45, 47, 4, 71, 87, 11, 67, 58, 9, ...Looks acceptable. I can change all column names at end for better visual
OK now lets do some charts.
df %>%
group_by(TEAMNAME) %>%
# I add the jitter to avoid overplottin where goals are scored in same minute o different games
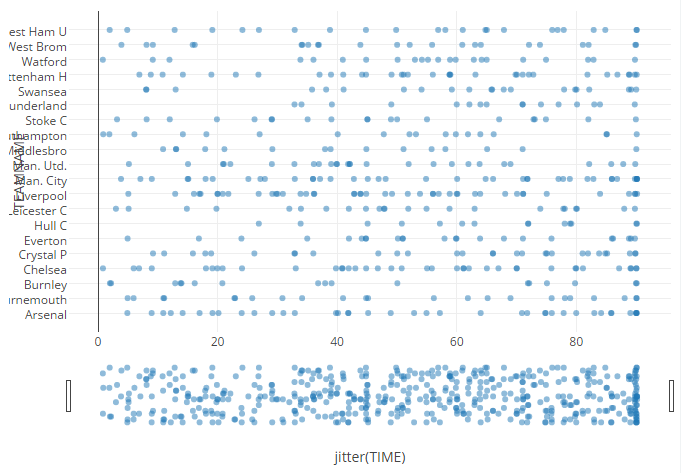
plot_ly(x=~jitter(TIME),y=~TEAMNAME) %>%
# I want to see all values
add_trace(type="scatter", alpha=0.5)## No scatter mode specifed:
## Setting the mode to markers
## Read more about this attribute -> https://plot.ly/r/reference/#scatter-modeSo we have the very definition of an exploratory chart. No title, meanigless or unnecessary axis titles, cut-off and mis-ordered axis data and and hoverinfo which does not exactly relate back to the underlying dataframe.
Never mind. By hovering or just inspection(plotly automatically supplies pan and zoom) we can see that Hull had not previously scored before the 27th minute.
A couple of other points came to me from a simple observation. No doubt you may have more
- A lot of goal get scored towards the end of games - does this vary by team
- Sunderland (not underland!) have fared even worse with no success until the 32nd minute in any of 18 games.. and counting
The first may be best solved by the addition of a rangeslider. Just move th handles close to the 90 minute mark
df %>%
group_by(TEAMNAME) %>%
# I add the jitter to avoid overplottin where goals are scored in same minute o different games
plot_ly(x=~jitter(TIME),y=~TEAMNAME) %>%
# I want to see all values
add_trace(type="scatter", alpha=0.5) %>%
rangeslider()Manchester City and Arsenal seem to have been particularly successful in this regard and on the to-do list is somehow to indicate which of these goals have an actual influence on the result of a game.
The other point of note is that every team - including Sunderland - has scored in the 90th minute (or beyond as I include time added on for injuries, substitutions and time-wasting as a 90th minute event) this season.
It makes sense that more goals are scored at the end of a game as teams strive for a winner or equalizer and leave themselves more prone to counter-attack but EVERY team? How likely is that?
No problemo. We have the data: let’s look back over the past 25 years
# We need to obtain the latest time in a game every team has scored in every season
goals %>%
# create data
left_join(playerGame) %>%
# order in time
arrange(desc(TIME)) %>%
# provide total coverage
group_by(TEAMNAME,season) %>%
# select the latest time in game
slice(1) %>%
# reduce to items of interest (if want to tabulate for example)
select(TEAMNAME,TIME, season) %>%
# introduce the filter
filter(TIME==90) %>%
# we want to see how this varies -if at all over the seasos
group_by(season) %>%
# count number of teams scoring at least once in the 90th+minute
summarise(count=n()) %>%
# and view as a barplot
plot_ly(x=~season, y=~count)Wow. that’s a bit bright! But it does show that this is a bit of a rarity. Only three other years with all 20 and one with 21 (the first three seasons of the Premier League featured 22 teams)
Let’s not forget that this is also prior to the half-way point in this season. How have other years stacked up after just 18 games. For this we will need to join another table (standings)
goals %>%
left_join(playerGame) %>%
# provides the tmYrGameOrder column
left_join(standings) %>%
# now restricting to first 18 games of season
filter(tmYrGameOrder<=18) %>%
arrange(desc(TIME)) %>%
group_by(TEAMNAME,season) %>%
slice(1) %>%
select(TEAMNAME,TIME, season) %>%
filter(TIME==90) %>%
group_by(season) %>%
summarise(count=n()) %>%
plot_ly(x=~season, y=~count)This provides a more striking chart, when tidied up, and could be a jumping off point for explanatory rather than exploratory analyses. Have there been more games close going into last few minutes, has the amount of extra time played increased this season are possible avenues which I will not pursue now. But, hey, if any of you do please let me know
One final point of interest is how Sunderland’s failure to score by 31st minute stacks up over the years. This just requires some small adjustments to the above code and a different method of presentation. I have also added the team’s final League position that year to give the finding some context
df <- goals %>%
left_join(playerGame) %>%
left_join(standings) %>%
filter(tmYrGameOrder<=18) %>%
# now want to arrange on ascending time
arrange(TIME) %>%
group_by(TEAMNAME,season) %>%
slice(1) %>%
arrange(desc(TIME)) %>%
# add in finishing position of team
select(team=TEAMNAME,first_goal=TIME, season, finished=final_Pos) %>%
data.frame()
df %>%
head(10)%>%
DT::datatable(width=500,class='compact stripe hover row-border order-column',rownames=FALSE,options= list(paging = FALSE, searching = FALSE,info=FALSE))So not the worst ever, even for Sunderland. Predictably, these teams usually finished in the bottom half but it is obviously not a great predictor of relegation (the 2016/17 shows position after 18 games)
So there you have it. With some interesting data and a passing knowledge of R it is pretty easy to come up with something